As a longtime fan of tabletop roleplaying games when the time to choose a data source for my Natural Language Processing project choosing campaign/adventure path books was an easy decision. I chose Starfinder due to my personal interest in the intersection of science fiction and fantasy elements. Throughout this project, I wanted to explore the overlap of topics and characterization (particularly of antagonists) among different adventure paths to look for emerging archetypes or themes. I used 7 adventure paths for a total of 33 individual books. The Starfinder adventure paths can be viewed here. A summary of my findings can be found in this presentation. This tableau dashboard is a deeper dive into my topic modeling showing the prevalence of different topics within the different adventure paths.
Tools Used
- Standard Tools
- Pandas, Numpy
- glob, Counter
- Text Preprocessing
- NLTK
- WordNetLemmatizer
- PorterStemmer
- stopwords
- RegexTokenizer
- re
- string
- NLTK
- Topic Modeling
- CountVectorizer
- TfidVectorizer
- NMF
- LDA
- Characterization
- spaCy
- Doc2Vec
- Visualization
- Matplotlib, Seaborn
- PIL Image
- WordCloud
Text Cleaning
After manual cleaning up some formatting issues that occurred from converting the book pdfs into text files I then loaded each file into a data frame as a base for future text cleaning. Looking at complete texts I did some initial EDA to visualize the contents of the different books in the forms of a document-term matrix and wordclouds. After testing multiple variations of separating the books into smaller texts I chose to separate my texts based on subsections within chapters.

While cleaning my text I converted all text to lowercase letters and removed punctuation, numbers, quotations, additional spacing, and line break syntax. I also removed words shorter than three characters as my text had many abbreviations and acronyms. I found stemming to remove a lot of the interpretability from my word tokens so I worked primarily with lemmatization. In addition to the standard nltk english stopwords, I added some stopwords that were specific to my texts.
Topic Modeling
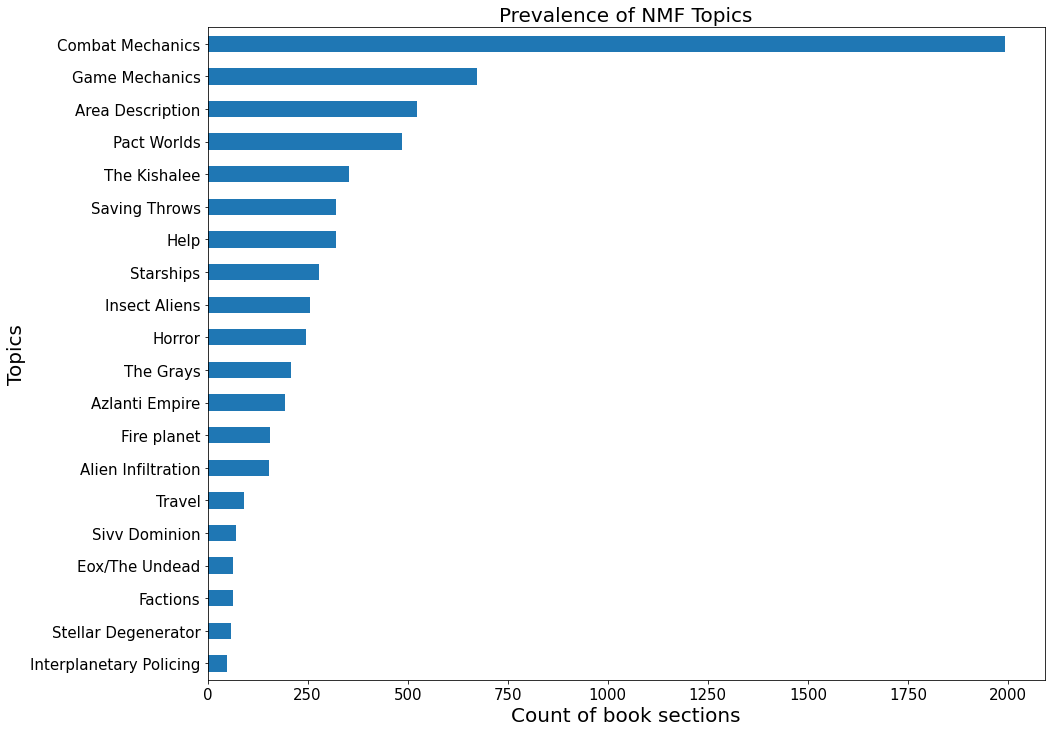
Using CountVectorizer I performed topic modeling on my text sections using Non-negative matrix factorization (NMF) and Latent Dirichlet allocation (LDA) to produce 20 topics. I found that NMF produced topics with less subject overlap than LDA therefore I chose to focus further on that type of topic modeling. I also tested NMF with TfidVectorizer which resulted in nearly identical topics to my original NMF modeling however the assignment of topics to subsections seems more accurate and consistent with the original version of the model so I chose the CountVecotrizer NMF version as my final topic model. I saved the top 20 keywords from each topic and used these keyword lists to determine the subject of each topic. Then I created a graph showing the distributions of each topic among the book subsections. My tableau dashboard further breaks this down by showing the number of sections labeled for each topic and the number of books each topic is present in as well as comparing the distribution of topics within each adventure path.
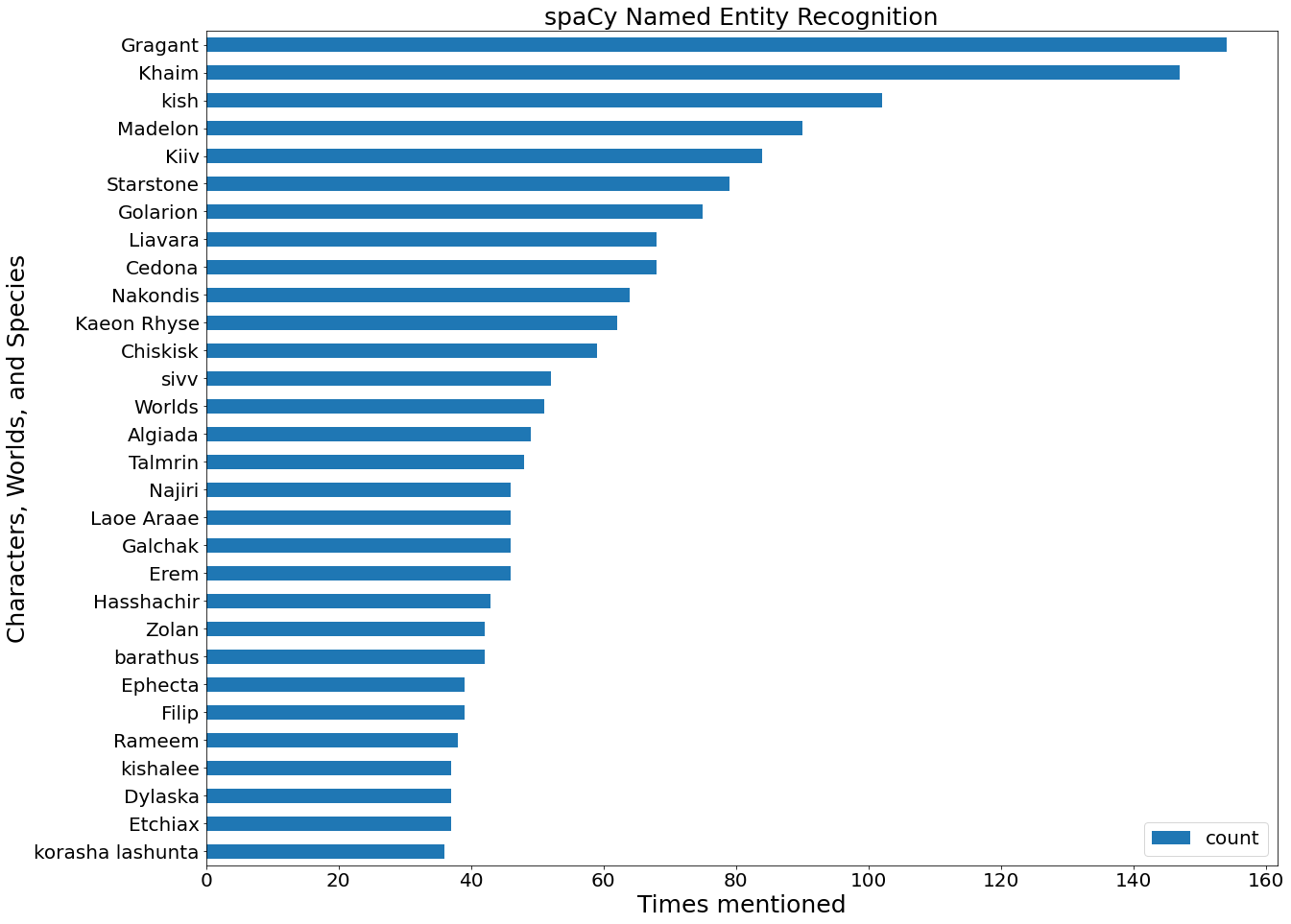
Named Entity Recognition and Characterizations
I was also interested in looking at the characterization of antagonists within different adventure paths to determine if there were certain character archetypes that appear more often than others and to view variations within character descriptions and motivations. Since Starfinder is a science-fantasy tabletop game there are a lot of words and names that don't appear in the real world I was concerned pre-trained models would not be able to determine what these words are, however, spaCy Named Entity Recognition had some success. While spaCy NER did have some difficulty differentiating between characters, alien worlds, and alien species the majority of named entities it returned when filtering for tokens labeled as 'PERSON' the majority of entities were in fact characters. A similar mixed success was also seen when filtering for Nationalities or religious or political groups ('NORP'). I used the number of times an entity to visualize the spaCy results, many of the most frequently mentioned characters such as Gragant and Khaim are antagonists for different adventure paths.
Once I was able to isolate individual characters from the text I began to explore methods of how to determine characterization for those individuals. I decided on using word embeddings from Doc2Vec using the inbuild similarity functions to look at words closely related to certain character names. At this point I went back to using whole books instead of subsections, I cleaned the text similar to how my subsections were cleaned and performed document tagging to prepare the texts for usage in Doc2Vec. Looking at the 'most_similar' function for antagonist characters I was able to create a list of characters, concepts, and descriptions closely related to those characters. I then created a function to look at similarities among characters comparing villains other villains, villains to 'good guys', and good guys to other good guys. Characters with similar backgrounds or motivations often scored higher regardless of character role. I also noticed characters from the same text also have a higher similarity scoring, using Word2Vec instead of Doc2Vec may alleviate this to put a greater emphasis on character traits.
| Character Name | Descriptors |
|---|---|
| Dr. Lestana Gragant | nightmares, corruption, sinister, carnage, clinical, transformed |
| Zolan Ulivestra | bureacracy, nobility, ambitious, mockingly, nihilistic, competitive |
| Serovox | admiral, supremacy, honor, duplicity, imprison, conquer |
| Khaim | general, conquer, invading, supremacy, retaliate, seized |
| Hadiya Najiri | commander, encourages, resourceful, rescued, befriend, glad |
Looking at a sample of the antagonists while many of the descriptors are quite different some of these characters have significant overlaps. These overlaps seen with Serovox and Khaim represent a similarity of background and or motivations, however the descriptors in which they do not overlap show how those characters go about meeting their goals are quite different. The character of Hadiya Najiri is not an antagonist, many of the antagonists had military backgrounds or connections so I was interested in looking at how a non-antagonist character with a military background may be characterized. One could infer from her positive characterization the prevelance of antagonists with military ties is due to those characters being in a position to abuse power rather than painting the entire institution as evil.
Conclusions, Impacts, and Future Work
The reuse of topics and characterization elements among different adventure paths allows for the creation of a cohesive game universe, but the differentiation in their usage among the adventure paths prevents excessive repetition of story and characters. This modeling workflow could be used to identify the popular topic and character archetypes in different texts. I'd like to apply this to more tabletop roleplaying books to see if certain topics or character archetypes are common among different roleplaying game systems or to compare and contrast these elements within very well-received game campaigns versus ones that were less well-liked.
My Repository
Here’s a link to my GitHub repository for this project for a closer look at the code used.
Comments